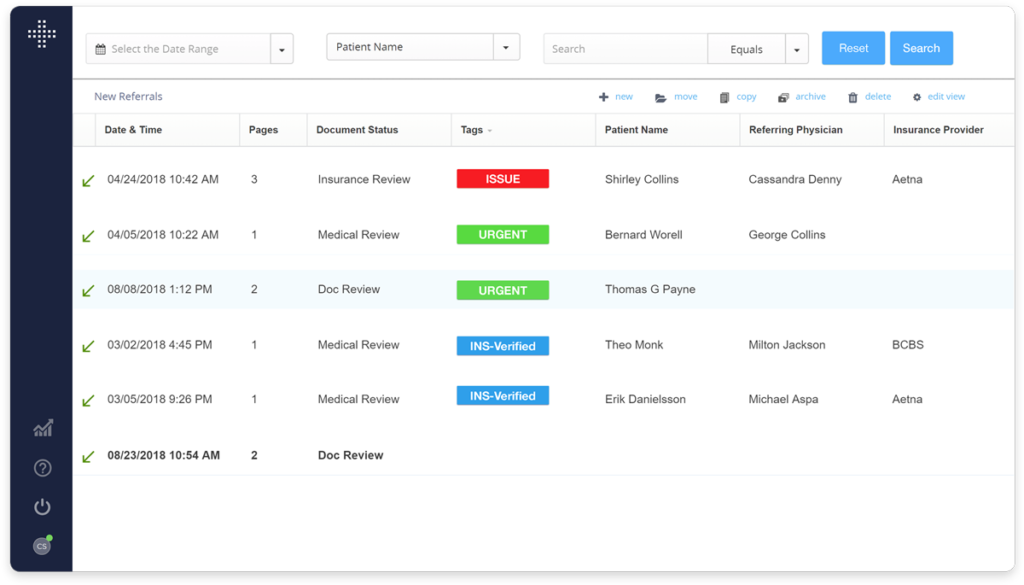
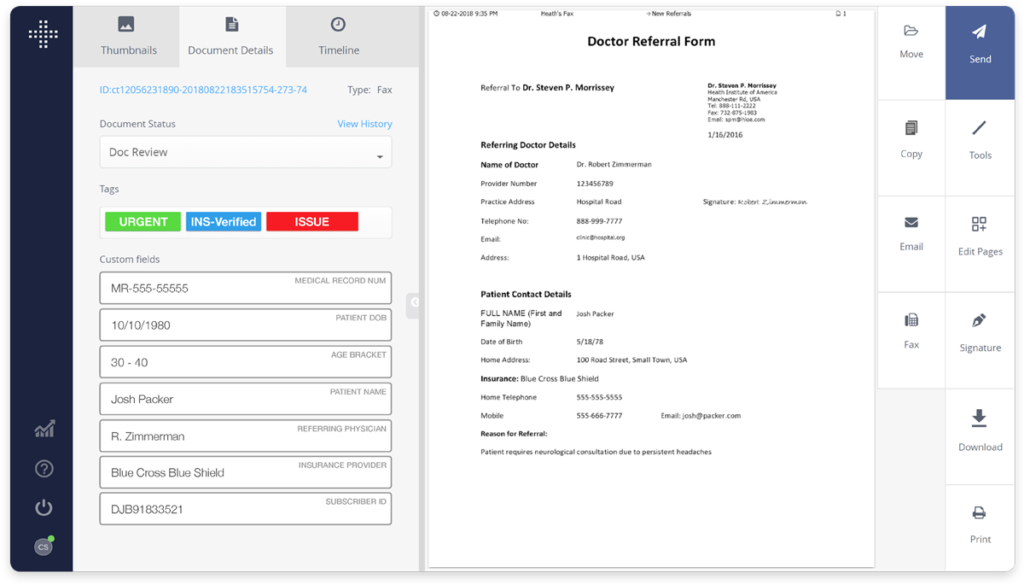
AI-powered application for extracting fields from diverse documents, offering rapid processing, customizable rules, and seamless integration with medical systems.
Efficiency and accuracy are essential in the realm of document processing and data extraction, especially when handling large volumes of information swiftly and reliably. Lektik introduces the Automated Document Capture project, an innovative solution that utilizes advanced AI techniques to extract defined fields from documents or images in various formats. This solution dramatically improves operational performance in settings where accuracy and speed are critical by processing healthcare documents in less than a second and delivering the extracted data via a REST API.
Business Context
The healthcare industry, along with others, is constantly under pressure to efficiently manage extensive documentation. Traditional methods of data extraction often struggle to handle diverse document formats and require substantial manual effort, resulting in delays and potential errors. This challenge calls for a sophisticated approach to document processing that can effectively manage the complexities of various document types while maintaining high accuracy and speed.
The Automated Document Capture project tackles these challenges by implementing a robust framework for intelligent field extraction. This framework seamlessly integrates with current medical document management systems and processes documents rapidly. The capability to add or review rules for data patterns further enhances its adaptability, making it a versatile tool for various document processing needs.
Key Features
Advanced Data Extraction: Utilizes sophisticated AI techniques to identify and extract necessary data from documents or images, ensuring precision and efficiency across diverse document formats.
Swift Processing: Processes healthcare documents within sub-second intervals, providing extracted fields via a REST API. This rapid processing capability is essential for environments requiring swift access to accurate data.
Customizable Extraction Parameters: Empowers users to incorporate or review rules and data patterns for extracting specific fields from various document types or images. This customization ensures adaptability to specific needs and continuous improvement over time.
Integration with Medical Document Management Systems: Integrates with existing medical document management systems, ensuring seamless access to extracted data within the workflow. This integration enhances overall document management process efficiency.
Solution Components
AI-Enabled Extraction Engine: Utilizes TensorFlow and OpenCV to drive the intelligent field extraction process, ensuring accurate identification and extraction of relevant data from diverse document types.
Data Access via REST API: The REST API facilitates rapid retrieval of extracted data, enabling seamless integration with other systems and applications. This API ensures real-time availability of data for further processing or analysis.
Adaptable Rule Management: Developed with Java and MongoDB, the rule management component allows users to define and adjust rules for data extraction. This adaptability ensures that the system can be customized to specific document processing requirements.
High-Performance Document Processing: Harnesses Leptonica for efficient image processing, ensuring swift and precise document processing. This component is crucial for maintaining the sub-second processing times necessary in high-demand environments.
Key Technologies
Java
mongoDB
Leptonica
TensorFlow
Open CV
Benefits
Improved Operational Efficiency: By automating the data extraction process and reducing the need for manual intervention, the solution significantly improves operational efficiency, leading to faster processing times and lower labor costs.
Enhanced Data Accuracy: The use of advanced AI techniques ensures high accuracy in data extraction, minimizing errors and ensuring the correct capture of critical information.
Real-Time Data Access: The REST API offers real-time access to the extracted data, enabling quicker decision-making and more efficient workflows.
Customizable and Expandable: The capability to add or modify extraction rules ensures that the system can adapt to various document types and processing requirements. This flexibility, combined with the scalable architecture, guarantees long-term usability and relevance.
Seamless Integration: Integration with existing medical document management systems ensures that the solution can be deployed without significant changes to current workflows, enhancing overall efficiency.
Conclusion
The Automated Document Capture project revolutionized data extraction and document processing within organizations. By amalgamating advanced AI techniques with a user-friendly, customizable framework, this solution addresses the critical need for speed, accuracy, and efficiency in document management. Its seamless integration with existing systems and real-time data accessibility further enriches its value, making it an indispensable tool for industries reliant on precise and efficient document processing.
Screenshot
Solutions Tailored to Your Needs
Need a tailored solution? Let us build it for you.