





Insights
/ Beyond the Screen: GameNGen’s AI-Powered World
Beyond the Screen: GameNGen’s AI-Powered World
Artificial Intelligence
Share this blog





Share this blog
The gaming industry has always been a domain of precisely calibrated software systems. The fundamental component of these systems is the game loop, a cycle of input gathering, state updates, and rendering that gives virtual worlds life. Despite countless technological and game engine advancements, the fundamental process of manual game development has remained largely unchanged. Recent advances in artificial intelligence, particularly in generative models, have offered an intriguing peek at a potential new shift in game development. Diffusion models have become a viable tool for this quest because of their reputation for producing high-quality photos and films. However, simulating interactive worlds involves unique challenges beyond basic video production.
Neural model simulation of interactive games presents certain difficulties, especially when conditioning on input actions available only during generation. To do this, an autoregressive technique must be used, which could lead to instability and sampling divergence. Despite these difficulties, positive attempts have been made, keeping in mind the problems with the game’s complexity, speed, stability, and visual quality. This blog is about GameNGen, a diffusion model trained to produce a game’s next frame based on a series of previous frames and actions. Its unique feature is its ability to emulate the venerable DOOM game at over 20 frames per second on a single TPU while maintaining visual fidelity close to the original. This achievement is more than just a technical marvel; it is a window into the future of AI-driven interactive experiences.
The architecture of GameNGen is based on Stable Diffusion v1.4, with some significant changes made to allow for real-time, interactive gameplay. The training of the model is divided into two stages:
This was made possible by the introduction of several significant innovations:
Noise Augmentation: It uses a unique noise augmentation method to reduce autoregressive drift, which usually causes a sudden quality reduction in sequential generation. Throughout the training, different levels of Gaussian noise are applied to encoded frames, and the model is fed an input corresponding to the noise level. This is essential for preserving quality over time because it enables the network to rectify information from previously sampled frames.
Latent Decoder Fine-Tuning: The pre-trained auto-encoder from Stable Diffusion v1.4 has been modified for DOOM frame generation to handle minute details and the HUD artifacts precisely.
Effective Inference: The model can remarkably reduce the number of DDIM sampling steps required to produce high-quality results from several dozen to just four. Compared to generative diffusion models, this is a major improvement. Only with such efficiency can real-time performance be achieved.
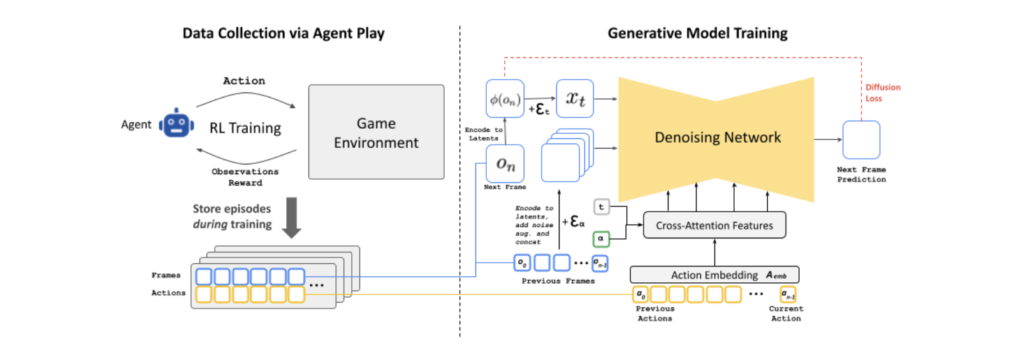
The agent model is trained using Proximal Policy Optimization (PPO) using Convolutional Neural Networks (CNNs) as the feature extractor, utilizing the Stable Baselines 3 framework. The agent receives downscaled frame photos, 160×120 in-game maps, and the last 32 acts it captured. Each image is processed by the feature network into a 512-dimensional representation. The actor-critic model in PPO computes the policy and value estimates using two-layer Multi-Layer Perceptron (MLP) heads. These heads concatenate the image characteristics with the history of actions. The agent is trained in the VizDoom environment using 512 replay buffers and eight games running in parallel. Training is done over 10 epochs with a batch size of 64, an entropy coefficient of 0.1, and a discount factor (γ) of 0.99. The network learns at a rate of 1e-4, performing ten million environment steps.
A batch size of 128 and a constant learning rate of 2e-5 are used to unfreeze the U-Net parameters and fine-tune a pre-trained checkpoint from Stable Diffusion 1.4 to train simulation models. Gradient clipping is set to 1.0, and Adafactor is used as the optimizer without weight decay. Re-parameterizing the diffusion loss to v-prediction, classifier-free guidance (CFG) is enabled during inference by deleting context frames at random with a chance of 0.1. Training is carried out via data parallelization among 128 TPU-v5e devices, with the majority of studies reaching 700,000 steps. Ten embedding buckets are used to apply noise augmentation, with a maximum noise level of 0.7. Large batch sizes of 2,048 are used to train the latent decoder, and other parameters are the same as those used for the denoiser.
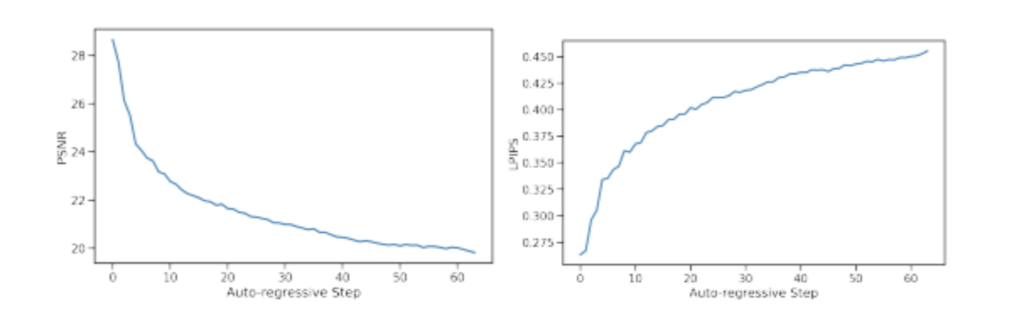
This approach to game simulation demonstrates remarkable accuracy to the original in terms of long-term trajectory reproduction and image quality. Results resembling lossy JPEG compression at quality settings of 20–30 were obtained from analytical testing using LPIPS and PSNR measures under teacher-forcing conditions. Even with small divergences in trajectory, the anticipated content under an autoregressive framework remained visually close to the game design. The Fréchet Video Distance (FVD) scores of 114.02 and 186.23 for 16-frame and 32-frame sequences, respectively, validate the effectiveness of the model.
GameNGen introduces a promising new way to create and play video games. Games are often created using human-written code, but GameNGen is a proof-of-concept for a time when neural model weights, rather than lines of code, will represent games. This technique suggests a game development landscape that may undergo significant change by showcasing the ability of a neural architecture to run a sophisticated game like DOOM interactively on current technology. This paradigm makes game creation and customization more accessible and affordable by allowing developers to design games or add new behaviors using written descriptions or sample images rather than manual coding.
Soon, it might be possible to generate new playable levels or characters without the need for complex algorithms by utilizing visual input like frames or photos. Beyond inventiveness, this innovative approach might provide more consistent performance, guaranteeing consistent memory utilization and frame rates on many platforms. To fully accomplish this goal, much more research and testing are needed, but GameNGen is an interesting first step. Along with changing how people play video games, this shift will lead to more substantial advancements in interactive software systems, which will get them closer to being dynamic and intuitive.
Need a tailored solution? Let us build it for you.
Connect Today
